Speech to Text#
This example will show you how to use GPTCache and OpenAI to implement speech to text, i.e. to turn audio into text. Where the OpenAI model will be used to turn the audio data, and GPTCache will cache the generated text so that the next time the same or similar audio is requested, it can be returned directly from the cache, which can improve efficiency and reduce costs.
This bootcamp is divided into three parts: how to initialize gptcache, running the openai model to turn audio data into text, and finally showing how to start the service with gradio. You can also find the colab in here. You can also try this example on Google Colab.
Initialize the gptcache#
Please install gptcache first, then we can initialize the cache. There are two ways to initialize the cache, the first is to use the map cache (exact match cache) and the second is to use the database cache (similar search cache), it is more recommended to use the second one, but you have to install the related requirements.
Before running the example, make sure the OPENAI_API_KEY environment variable is set by executing echo $OPENAI_API_KEY. If it is not already set, it can be set by using export OPENAI_API_KEY=YOUR_API_KEY on Unix/Linux/MacOS systems or set OPENAI_API_KEY=YOUR_API_KEY on Windows systems.
1. Init for exact match cache#
cache.init is used to initialize gptcache, the default is to use map to search for cached data, pre_embedding_func is used to pre-process the data inserted into the cache, and it will use the get_file_bytes method, more configuration refer to initialize Cache.
# from gptcache import cache
# from gptcache.adapter import openai
# from gptcache.processor.pre import get_file_bytes
# cache.init(pre_embedding_func=get_file_bytes)
# cache.set_openai_key()
2. Init for similar match cache#
When initializing gptcahe, the following four parameters are configured:
pre_embedding_func: pre-processing before extracting feature vectors, it will use theget_file_namemethodembedding_func: the method to extract the text feature vectordata_manager: DataManager for cache managementsimilarity_evaluation: the evaluation method after the cache hit
The data_manager is used to audio feature vector, response text in the example, it takes Milvus (please make sure it is started), you can also configure other vector storage, refer to VectorBase API.
from gptcache import cache
from gptcache.adapter import openai
from gptcache.processor.pre import get_file_name
from gptcache.embedding import Data2VecAudio
from gptcache.similarity_evaluation.distance import SearchDistanceEvaluation
from gptcache.manager import get_data_manager, CacheBase, VectorBase, ObjectBase
data2vec = Data2VecAudio()
cache_base = CacheBase('sqlite')
vector_base = VectorBase('milvus', host='localhost', port='19530', dimension=data2vec.dimension)
data_manager = get_data_manager(cache_base, vector_base)
cache.init(
pre_embedding_func=get_file_name,
embedding_func=data2vec.to_embeddings,
data_manager=data_manager,
similarity_evaluation=SearchDistanceEvaluation(),
)
cache.set_openai_key()
Run openai speech to text#
Then run openai.Audio.translations, which can translate and transcribe the audio into english, and it is based on large-v2 Whisper model. The file uploads are currently limited to 25 MB and the following input file types are supported: mp3, mp4, mpeg, mpga, m4a, wav, and webm.
Note that openai here is imported from gptcache.adapter.openai, which can be used to cache with gptcache at request time. Please download the blues.00000.mp3 before running the following code.
audio_file= open("./blues.00000.mp3", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file)
print(transcript["text"])
One bourbon, one scotch and one bill Hey Mr. Bartender, come here I want another drink and I want it now My baby she gone, she been gone tonight I ain't seen my baby since night of her life One bourbon, one scotch and one bill
Start with gradio#
Finally, we can start a gradio application to translate and transcribe the audio.
First define the speech_to_text method, which is used to generate text based on the input audio and also return whether the cache hit or not. Then start the service with gradio, as shown below:
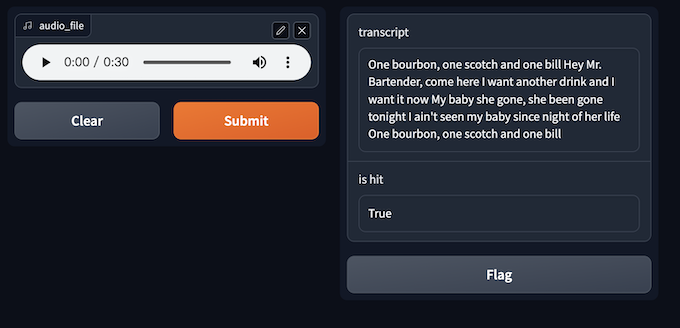
def speech_to_text(audio_file):
audio_file= open(audio_file, "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file)
return transcript["text"], transcript.get("gptcache", False)
import gradio
interface = gradio.Interface(speech_to_text,
gradio.Audio(source="upload", type="filepath"),
[gradio.Textbox(label="transcript"), gradio.Textbox(label="is hit")]
)
interface.launch(inline=True)